Metoda prognozy produkcji energii wiatrowej z horyzontem jednodniowym oparta na algorytmach sztucznej inteligencji
Day-Ahead Wind Power Forecasting Method Based on AI Algorithms

Łączna moc wszystkich turbin wiatrowych na świecie w 2023 r. przekroczyła 1051 gigawatów, fot. Pixabay
Rozwój współczesnej energetyki zmierza w kierunku uzyskania największego udziału energii odnawialnej w bilansie energetycznym, reprezentowanej przez energię wiatrową pozyskiwaną z turbin oraz energię słoneczną pozyskiwaną z paneli fotowoltaicznych [1, 2]. Przewaga energetyki wiatrowej nad słoneczną wynika z jej większych zasobów środowiskowych oraz bardziej efektywnej technologii wytwarzania energii [3, 4].
Zobacz także
dr hab. inż. Paweł Piotrowski, dr hab. inż. Dariusz Baczyński, prof. uczelni, mgr inż. Marcin Kopyt, inż. Rafał Aspras, inż. Hubert Dryja, inż. Paweł Makowski, inż. Kamil Samul Analiza statystyczna danych oraz prognozy generacji energii w farmie wiatrowej z wyprzedzeniem do 24 godzin (część 1.)
Dokładne prognozy generacji energii w farmach wiatrowych są bardzo ważną informacją umożliwiającą efektywne planowanie i sterowanie pracą sieci elektroenergetycznej.
Dokładne prognozy generacji energii w farmach wiatrowych są bardzo ważną informacją umożliwiającą efektywne planowanie i sterowanie pracą sieci elektroenergetycznej.
dr inż. Andrzej Książkiewicz - Astat Sp. z o.o. Energoelektroniczne kompensatory mocy biernej ASTec SVG dużej mocy

Rosnące wymagania dotyczące jakości energii elektrycznej oraz dynamiczna zmienność obciążeń w zakładach przemysłowych czynią kompensację mocy biernej kluczową z perspektywy technicznej i ekonomicznej....
Rosnące wymagania dotyczące jakości energii elektrycznej oraz dynamiczna zmienność obciążeń w zakładach przemysłowych czynią kompensację mocy biernej kluczową z perspektywy technicznej i ekonomicznej. W obliczu wzrastających kosztów energii biernej oraz konieczności spełnienia rygorystycznych norm, coraz większą rolę odgrywają nowoczesne rozwiązania, takie jak statyczne generatory mocy biernej (SVG) o prądzie znamionowym 150 A i 200 A. Dzięki zaawansowanym parametrom, możliwościom rozbudowy i dynamicznej...
dr inż. Andrzej Książkiewicz - Astat Sp. z o.o. Stabilizacja napięcia w układach zasilania obiektów krytycznych – rozwiązania MSR i MST

Wahania napięcia w sieciach elektrycznych to powszechny problem, który może prowadzić do awarii urządzeń czy przerw w produkcji. Według normy PN-EN 50160, dopuszczalne odchylenia napięcia to ±10%, jednak...
Wahania napięcia w sieciach elektrycznych to powszechny problem, który może prowadzić do awarii urządzeń czy przerw w produkcji. Według normy PN-EN 50160, dopuszczalne odchylenia napięcia to ±10%, jednak wiele urządzeń przemysłowych wymaga znacznie wyższej stabilności.
W artykule:
|
StreszczenieTematem artykułu jest przedstawienie metodologii predykcji produkcji energii wiatrowej w horyzoncie jednodniowym z wykorzystaniem metod regresji bazujących na algorytmach sztucznej inteligencji: maszyn faktoryzujących, drzew decyzyjnych oraz lasów losowych. Dane SCADA poddane analizie pochodzą z farmy wiatrowej zlokalizowanej w Turcji i zostały wstępnie przetworzone w celu ułatwienia zadania predykcyjnego. AbstractThe subject of this paper is the presentation of the forecasting methodology for wind energy production in a one-day time horizon using regression methods based on artificial intelligence algorithms: factoring machines, decision trees and random forests. The analyzed SCADA data comes from a wind farm located in Turkey and has been pre-processed to facilitate the prediction task. |
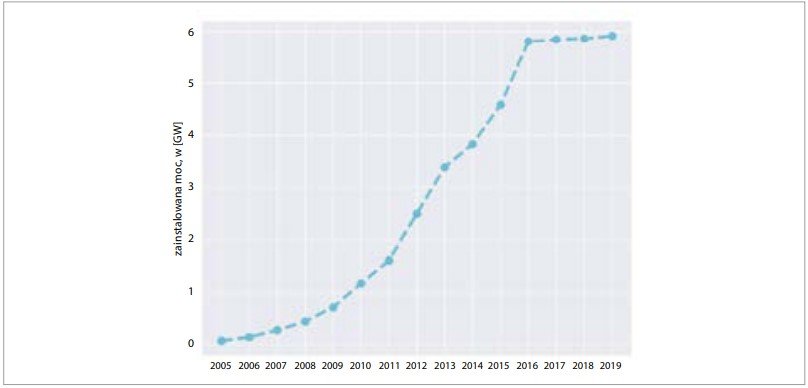
Według Światowego Stowarzyszenia Energetyki Wiatrowej (World Wind Energy Association – WWEA), łączna moc wszystkich turbin wiatrowych w 2021 r. przekroczyła 840 gigawatów (rys. 1.) [5]. Jest to wzrost o 107,5 gigawatów w stosunku do roku 2020 i zapewnia ponad 7% światowego zapotrzebowania na energię. Czyni to z energetyki wiatrowej niezbędny element zrównoważonego rozwoju energetyki na świecie oraz procesu ograniczania zanieczyszczenia środowiska w wyniku spalania surowców kopalnych.

Rys. 1. Globalna skumulowana zainstalowana moc wiatrowa w latach 2015–2021 [5]
Rosnący udział energii wiatrowej w światowym bilansie energetycznym to wyzwanie dla sieci i systemów elektroenergetycznych, którego źródłem jest zmienność warunków wietrzności oraz rozproszony charakter systemów generujących energię wiatrową. Planowanie lokalizacji pod budowę farm wiatrowych – zarówno lądowych, jak i morskich – wymaga skrupulatnej oceny środowiska, w jakim powstaną nowe tego typu struktury, celem zapewnienia długotrwałej wydajności turbin wiatrowych i atrakcyjnych zwrotów z inwestycji.
W przypadku wiatrowej energetyki lądowej innowacje technologiczne związane są ze zwiększaniem produktywności na obszarach o niekorzystnych warunkach wiatrowych. Próbą sprostania temu dylematowi jest eksploatacja turbin z długimi łopatami oraz wysokimi wieżami. Maksymalna wysokość lądowych turbin wiatrowych jest często ograniczona niekorzystnymi warunkami środowiskowymi jak również brakiem akceptacji społecznej dla tego typu struktur, co ogranicza zakres możliwych innowacji na tym polu.
Wielkość turbin nie ma natomiast znaczenia w segmencie morskiej energetyki wiatrowej. Tu innowacje skupiają się na projektowaniu większych turbin, które pozwalają na obniżenie ogólnych kosztów wytwarzania energii.
Równolegle przyspiesza rozwój konkurencyjnych pod względem kosztów oraz bezpieczeństwa mobilnych morskich turbin wiatrowych. Pływające farmy wiatrowe mogą odblokować ogromny potencjał obszarów oceanicznych o głębokości wody zbyt dużej dla turbin stacjonarnych i mogą być istotnym narzędziem transformacji energetycznej dla krajów takich jak Japonia, Korea Południowa, Portugalia, Francja oraz zachodnie wybrzeże Stanów Zjednoczonych.
Obecnie najbardziej wydajnym rodzajem turbiny wiatrowej jest trójpłatowa konstrukcja z osią poziomą. Na świecie wdrożono już 300 000 tego typu turbin. Ich pracę optymalizuje specjalnie opracowane dla nich oprogramowanie.
Nowoczesna turbina wiatrowa zaczyna wytwarzać energię przy prędkości wiatru wynoszącej ok. 3 m/s i jest wyłączana, gdy przekroczy 24 m/s. W celu uniknięcia zagrożenia uszkodzenia mechanizmu generacji energii, większość turbin wiatrowych pracuje z wydajnością 30–40%, chociaż w idealnych warunkach wiatrowych wzrasta ona nawet do 50%.
Szacuje się, że przeciętna lądowa turbina wiatrowa o mocy 2,5–3 MW może wyprodukować ponad 6 milionów kWh rocznie. Turbina przybrzeżna o mocy 3,6 MW może ten rezultat podwoić.
Duża zmienność wytwarzania energii w czasie, wykazywana przez turbiny wiatrowe, jest głównym powodem, dla którego operatorzy systemów elektroenergetycznych wymagają od właścicieli farm wiatrowych prognozowania mocy elektrowni wiatrowych. Tego typu prognozy, w zależności od przyjętego horyzontu czasowego, mają zastosowanie m.in. w bilansowaniu podaży i zapotrzebowania na energię elektryczną w całym systemie elektroenergetycznym, optymalizacji obciążenia oraz planowaniu rezerw mocy [6]. Przygotowanie obarczonych możliwie najmniejszym błędem prognoz, choć niezwykle ważne z punktu widzenia zapewnienia niezawodności pracy całego systemu elektroenergetycznego i minimalizacji kosztów finansowych uczestnictwa w obrocie na rynku energii elektrycznej, jest zadaniem niezwykle problematycznym.
Niepewność w przewidywaniu warunków wiatrowych, wahania mocy, wynikające z niedoskonałości technologii wytwarzania energii wiatrowej oraz zmiennych warunków pogodowych, a także położenie geograficzne turbiny – to kluczowe czynniki wpływające na jakość prognoz ilości wytwarzanej energii wiatrowej przez turbiny [7].
Dane pozyskane z pracy farm wiatrowych przez systemy monitoringu mogą przechowywać m.in. informacje na temat średnich prędkości i średniego kierunku wiatru w określonych przedziałach czasu, długości okresów ciągłej pracy turbiny, rodzaju, mocy oraz napięcia pracy generatora itp. Podstawowym narzędziem do analizy pracy farmy wiatrowej jest diagram róży wiatrów (wiatrogram), demonstrujący rozkład kierunku i prędkości wiatru w danej lokalizacji.
Wiatr to ruch powietrza względem powierzchni ziemi, wywołany przez różnicę ciśnień i różnice w ukształtowaniu powierzchni. Powietrze przemieszcza się z obszaru o wyższym ciśnieniu do obszaru o niższym ciśnieniu.
Łopaty turbiny wiatrowej, przez którą przepływa wiatr, wytwarzają różnicę ciśnień powietrza, wytwarzającą siłę nośną i opór. Kiedy siła nośna jest większa niż opór, wały wirnika zaczynają się obracać, napędzając tym generator wytwarzający energię elektryczną [8, 9].
Energia kinetyczna powietrza przelatującego w czasie t przez powierzchnię A jest wyrażona wzorem (1):

gdzie:
v – prędkość wiatru,
ρ – gęstość powietrza,
Avt – objętość powietrza przelatującego przez powierzchnię A,
Avtρ – masa powietrza.
Energia na jednostkę czasu i powierzchni (powierzchniowa gęstość mocy) opisana jest wzorem (2):

Ze wzoru (2) wynika, że wiatr o dwukrotnie większej prędkości może dostarczyć ośmiokrotnie więcej mocy. Dlatego też lokalizacja turbiny wiatrowej jest kluczowa dla jej efektywności [10].
Horyzont predykcji to przyszły okres czasu, dla którego prognozowana będzie generacja wiatrowa. Powszechny jest podział horyzontów predykcyjnych ze względu na zastosowania, choć należy zaznaczyć, że nie istnieje ujednolicony i ścisły standard takiego podziału. Autorzy [11] dokonali podziału horyzontów predykcji na cztery kategorie: bardzo krótkoterminowe, krótkoterminowe, średnioterminowe oraz długoterminowe (tab. 1.).

Tab. 1. Klasyfikacja horyzontów czasowych predykcji generacji wiatrowej
Wraz ze wzrostem horyzontu predykcji spada dokładność predykcji [12, 13].
Modele prognozowania energii wiatrowej
W tabeli 2. przedstawiono porównanie współczesnych metod prognozowania prędkości wiatru. Można je podzielić na pięć kategorii: metody zachowawcze (ang. persistence methods), metody fizyczne (ang. physical methods), metody statystyczne (ang. statistical methods), metody oparte na sztucznej inteligencji (ang. artificial intelligence models) oraz metody hybrydowe (ang. hybrid methods).

Tab. 2. Porównanie współczesnych metod prognozowania generacji wiatrowej
Metoda zachowawcza to najczęściej stosowana metoda wzorcowa spośród wszystkich technik przewidywania. Zakłada ona, że prognozowana moc generacji wiatrowej w przyszłej chwili czasowej (t+1) jest taka sama jak wielkość mocy zmierzona w chwili tworzenia prognozy t, P(t+1) = P(t) [14]. Metoda ta daje najlepsze wyniki w prognozowaniu krótkoterminowym (np. godzinnym), jednak wraz ze wzrostem horyzontu prognozowania jej błąd prognozowania szybko rośnie. Wynika to z faktu rozmieszczenia farm wiatrowych na znacznym obszarze, co sprawia, że poszczególne jednostki nie są w stanie jednocześnie reagować na zmianę prędkości wiatru.
Metody fizyczne określają korelację między modelowanymi zjawiskami atmosferycznymi a generacją wiatrową. Do poprawnego działania wykorzystują historyczne dane meteorologiczne, tj. prędkość i kierunek wiatru, temperaturę, ciśnienie, wilgotność, chropowatość powierzchni itp. Modelowanie fizyczne wymaga znacznych zasobów obliczeniowych i długo się je wykonuje. Numeryczna prognoza pogody (NWP – Numerical Weather Prediction) to uproszczona technika przewidywania fizycznego. Dane NWP są aktualizowane raz na kilka godzin. Na działanie NWP wpływ mają czynniki fizyczne, które ograniczają dokładność modelu predykcyjnego NWP [15]. W związku z tym tego typu metoda jest bardziej odpowiednia do prognozowania średnio- oraz długoterminowego.
Metoda statystyczna nie wymaga modelowania matematycznego i do prognozowania wykorzystuje przeszłe prognozy. Metoda ta ustanawia zależności statystyczne między wielkościami generacji wiatrowej a prognozowanymi wielkościami meteorologicznymi, tj. prędkością i kierunkiem wiatru, temperaturą, ciśnieniem atmosferycznym itp. Wartość rzeczywista generacji służy w tym wypadku do wyznaczenia błędów prognoz. Tego typu metoda prognozowania zapewnia najlepszą skuteczność w horyzoncie krótkoterminowym [16].
Skok w rozwoju mocy obliczeniowej współczesnych komputerów na przestrzeni ostatnich dwudziestu lat umożliwił szerokie wykorzystanie algorytmów sztucznej inteligencji do analizy meteorologicznych danych Big Data. Główną ich zaletą jest potencjał do wyodrębniania wzorców z danych nieliniowych [17]. Wiele z tego typu technik wykorzystuje sztuczne sieci neuronowe (ANN – Artificial Neural Networks), maszyny wektorów nośnych (SVM – Support Vector Machines), logikę rozmytą, obliczenia ewolucyjne oraz uczenie maszynowe. Najczęściej używane sieci neuronowe to sieci jednokierunkowe (feed-foreward neural networks), sieci radialne (RBNN – Radial Basis Neural Networks) i rozmyte sieci neuronowe [18, 19].
W [20] autorzy wykorzystują regresory wektorów nośnych (SVR – Support Vector Regressor) do krótkoterminowego prognozowania energii wiatrowej, używając zmodyfikowanego algorytmu Dragonfly (wariant metodologii behawioralnej roju) do celów optymalizacji, aby zwiększyć dokładność prognoz. W pracy [21] te same regresory wykorzystano do prognozowania prędkości wiatru, z algorytmem bezgradientowym Jaya (metoda populacyjna, która wielokrotnie modyfikuje populację poszczególnych rozwiązań) jako optymalizatorem. Autorzy [22] stworzyli hybrydowy model prognostyczny oparty na konwolucyjnych sieciach neuronowych i algorytmie Informer (struktura sieci oparta na mechanizmie uwagi, przeznaczona do rozwiązywania problemu predykcji danych długich szeregów) do krótkookresowej predykcji energii wiatrowej. W [23] autorzy zaproponowali hybrydowy system prognozowania prędkości wiatru. Proponowana metoda opiera się na sieci neuronowej z propagacją wsteczną błędu, zaimplementowanej w celu uzyskania wyników predykcji, które są dekonstruowane na przedziały, zgodnie z klasyfikacją różnych cech danych za pomocą rozmytych klastrów.
W celu poprawy dokładności predykcji krótkoterminowej, techniki dekompozycji danych (EMD – Empirical Mode Decomposition) są łączone z algorytmem maszyn uczonych ekstremalnie (ELM – Extreme Learning Machines) [24, 25]. Istotą EMD jest wygładzenie szeregów czasowych, dekompozycja sygnału oryginalnego na kilka funkcji (IMF – Intrinsic Mode Function) oraz wyznaczenie podstawowych charakterystyk efektywnych sygnałów w danych [26], co może skuteczniej odzwierciedlać rozkład energii w skali przestrzennej (lub czasowej) w procesie fizycznym [27]. EML to sieci jednokierunkowe (feedforeward) z przynajmniej jedną warstwą ukrytą węzłów, których parametry – wraz z wagami, które łączą je z wejściem – są poddawane dopasowaniu. Ukryty węzeł może być w tym przypadku rozumiany jako typowy sztuczny neuron, funkcja bazowa, tudzież podsieć zbudowana z jakichś ukrytych węzłów.
Do optymalizacji wag w modelach opartych na ANN były wykorzystywane również techniki ewolucyjne, takie jak algorytm genetyczny (GA – Genetic Algorithm) oraz algorytm roju (PSO – Particle Swarm Optimization). W efekcie autorom [28, 29] udało się zredukować czas obliczeniowy zaproponowanego modelu oraz usprawnić proces uczenia sieci neuronowej.
Metody oceny modelu predykcji
Do oceny efektywności i wydajności zastosowanego modelu prognostycznego zwykle wykorzystywane są miary średniego absolutnego błędu MAE (Mean Absolute Error), błędu średniokwadratowego RMSE (Root-Means-Square Error) oraz współczynnika determinacji R2 (Coefficient of Determination) (tab. 3.) [30].

Tab. 3. Wskaźniki ewaluacji efektywności metody predykcji energii wiatrowej
MAE liczy się jako sumę błędów bezwzględnych podzieloną przez wielkość próby. RMSE to pierwiastek ze średniej kwadratowej różnicy między wartościami rzeczywistymi a przewidywanymi. Współczynnik R2 informuje o tym, jaka część zmienności zmiennej objaśniającej w próbie pokrywa się z korelacjami ze zmiennymi zawartymi w modelu. Jest to zatem miara dopasowania modelu do próby, które jest tym lepsze, im bliższa jedności jest wartość R2.
Charakterystyka danych
Farmy wiatrowe podłączone są do systemu SCADA (Supervisory Control and Data Acquisition), który na bieżąco gromadzi dane o pracy turbin wiatrowych. Rejestrowane dane obejmują m.in. wytwarzaną moc, kierunek i prędkość wiatru. Informacje te mogą być wykorzystane do dalszych analiz, takich jak ocena wydajności turbiny wiatrowej czy prognoza generowanej mocy. Jakość zbioru danych w istotnym stopniu determinuje dokładność i czas obliczeń modelu predykcyjnego. Dane wykorzystane na potrzeby niniejszego artykułu pochodzą z turbiny wiatrowej zlokalizowanej w miejscowości Esenköy w Turcji. Jej współrzędne geograficzne to 40.616118° szerokości oraz 28.955617° długości geograficznej (rys. 2.).

Rys. 2. Położenie geograficzne farmy wiatrowej Esenköy (Google Maps)
Zbiór danych zawiera 50 530 obserwacji, które zawierają informacje na temat:
- daty i godziny zarejestrowanego pomiaru; odczyty rejestrowane są w odstępach 10-minutowych;
- mocy generowanej przez turbinę, zarejestrowanej w danym momencie i wyrażonej w kW;
- prędkości wiatru na wysokości piasty turbiny wyrażonej w m/s;
- teoretycznej wartości mocy podanej przez producenta turbiny wiatrowej z uwzględnieniem określonej siły wiatru (Theoretical PowerCurve) – wartości te wyrażone są w KWh;
- kierunku wiatru w stopniach (°) mierzonego na wysokości piasty turbiny (jest to kierunek, w którym automatycznie obracają się turbiny wiatrowe).
Tabela 4. zawiera przykładowe wartości zbioru SCADA pozyskanego z pracy turbiny w miejscowości Esenköy. Tego typu tabelaryczne dane liczbowe są dostarczane algorytmowi sztucznej inteligencji jako informacja wejściowa, na podstawie której algorytm tworzy zestaw predykcji (również wyrażonych w postaci wartości liczbowych) z dziennym horyzontem czasowym.

Tab. 4. Pierwsze pięć przykładów ze zbioru SCADA Esenköy
Rysunki 3. i 4. przedstawiają odpowiednio godzinową i miesięczną średnią produkcję energii. Na rysunku 5. przedstawiono wykres biegunowy z prędkością wiatru, kierunkiem wiatru i produkcją energii z zebranego zestawu danych.

Rys. 3. Średnia godzinowa produkcja energii, rys. A. Bilski

Rys. 4. Średnia miesięczna produkcja energii, rys. A. Bilski

Rys. 5. Biegunowy wykres produkcji energii elektrycznej z wiatru, w zależności od jego kierunku i prędkości, rys. A. Bilski
W oparciu o te dane można stwierdzić, że średnia produkcja energii jest wyższa w marcu, sierpniu i listopadzie oraz pod koniec każdego dnia (po godzinie 16.00). Największą ilość energii można wytworzyć, jeśli wiatr wieje z kierunków 0–90 stopni oraz 180–225 stopni. Związane jest to z położeniem geograficznym turbiny.
Przygotowanie danych do analizy
Aby dane SCADA mogły być właściwie wykorzystane przez algorytm predykcji, muszą zostać odpowiednio oczyszczone. Ze zbioru usunięto wszystkie wartości, dla których siła wiatru nie przekraczała 2 m/s. Wynika to z faktu, że zgodnie z deklaracją producenta turbiny wiatrowej, turbina rozpoczyna pracę przy prędkości wiatru co najmniej 3 m/s. Jak pokazano na rysunku 6., produkcja energii jest najniższa przy prędkości 5 m/s, podczas gdy poziom bliski maksymalnemu osiągany jest przy prędkości wiatru wynoszącej około 15 m/s. Parametry te silnie zależą od konkretnego modelu turbiny wiatrowej.

Rys. 6. Uśredniona produkcja energii dla interwałów prędkości wiatru wynoszących 5 m/s, rys. A. Bilski
Następnie podczas estymacji modelu brakujące dane w zbiorze danych SCADA są ignorowane. Uzupełnienie luk metodami statystycznymi okazało się niemożliwe ze względu na dużą zmienność danych. Obciążyłoby to ostateczny model prognostyczny.
Dane podzielono w stosunku 4/1, gdzie 80% obserwacji (tj. 40 321 przykładów) wykorzystano do skonstruowania zbioru uczącego, służącego do estymacji parametrów metody prognostycznej, zaś 20% obserwacji (tj. 10 209 przykładów) wykorzystano jako dane testowe, oceniające dokładność przewidywania.
Wartości ekstremalne również zostały usunięte z zestawu danych. Wśród nich znalazły się wartości produkcji energii, które były zdecydowanie za niskie dla danej prędkości wiatru. Z dostępnych danych wynika, że są takie miesiące w roku, kiedy wiatrak nie wytwarza prądu, mimo że średnia prędkość wiatru utrzymuje się na poziomie 4 m/s. Być może w tym okresie turbina nie działała prawidłowo. Dlatego też wszystkie takie wartości (łącznie 3497 obserwacji) zostały wyłączone ze zbioru danych, aby ułatwić proces uczenia.
Opisane operacje wstępnego przetwarzania danych pozwoliły na przygotowanie danych bezpośrednio do budowy modeli prognostycznych, które następnie można było trenować i porównywać pod względem dokładności prognozy.
Metodologia autorska
Rysunek 7. przedstawia proces prognozowania energii wiatrowej z wykorzystaniem współczesnych metod regresji sztucznej inteligencji.

Rys. 7. Schemat przepływu danych w zaproponowanej metodologii prognozowania energii wiatru na podstawie algorytmów regresji, rys. A. Bilski
Można go podzielić na trzy etapy: uczenie i testowanie algorytmu oraz ocena jakości proponowanej metodologii predykcji. Podczas etapu uczenia korelacja między wejściowymi zmiennymi procesowymi a zmienną wyjściową jest ustalana na podstawie obserwacji ze zbioru danych SCADA, które są znane algorytmowi. W fazie testowania algorytm sztucznej inteligencji ma za zadanie przewidzieć wartości wyjściowe (energia wiatrowa) dla nieznanych danych wejściowych.
Algorytmy sztucznej inteligencji wykorzystane w tym badaniu to regresja faktoryzowana (Factorized Regression), regresja lasów losowych (Random Forests Regression) i drzewa decyzyjne (Decision Trees). Jakość każdego algorytmu na tego typu danych została oceniona za pomocą ewaluatorów regresji. Każdy algorytm został zaimplementowany w pysparku, który jest interfejsem dla Apache Spark w języku programowania Python. Wykorzystuje on bibliotekę uczenia maszynowego MLlib do celów klasyfikacji i regresji danych tabelarycznych DataFrame.
Maszyny faktoryzowane (Factorized Machines) to rozszerzenie modelu regresji liniowej, zaprojektowane w celu uchwycenia związków między cechami w wielowymiarowych rozproszonych zbiorach danych (te same informacje mogą być reprezentowane przy użyciu dużo mniejszej liczby zmiennych):

gdzie:
w0 – odchylenie (bias),
w – waga i-tej zmiennej,
vi – i-ta cecha,
<•,•> – iloczyn skalarny dwóch wektorów.
<vi, vj> modeluje relację między i-tą i j-tą cechą. W celu osiągnięcia dobrej generalizacji wykorzystano maszyny dwukierunkowe (2-Way Factorization Machines).
Drzewo decyzyjne wykonuje rekurencyjne binarne partycjonowanie przestrzeni cech, w którym drzewo przewiduje tę samą etykietę dla każdego liścia. Każda partycja jest wybierana chciwie. Odbywa się to poprzez wybranie najlepszego podziału cech dla zestawu wszystkich możliwych podziałów. Miarą zanieczyszczenia (miarą jednorodności etykiet w węźle) jest wariancja:

gdzie:

Maksymalna głębokość drzewa to 5.
Lasy losowe to zbiór drzew decyzyjnych. Łączą one wiele drzew decyzyjnych w celu zmniejszenia ryzyka nadmiernego dopasowania. Lasy losowe oddzielnie szkolą zestaw drzew decyzyjnych, aby umożliwić równoległe uczenie. Proces uczenia każdego drzewa jest losowy. Wariancja predykcji jest na końcu łączona, aby poprawić wydajność algorytmu. Każde drzewo decyzyjne przewiduje rzeczywistą wartość, która następnie jest uśredniana w celu przewidzenia nowej etykiety (rys. 8.).

Rys. 8. Model tworzenia lasów losowych, rys. A. Bilski
Wyniki eksperymentu
W celu przetestowania jakości podanych wyżej algorytmów regresji wykreślono krzywą mocy farmy wiatrowej w odniesieniu do prędkości wiatru na podstawie danych zawartych w zbiorze SCADA z Esenköy oraz wartości przewidywanych. Na rysunku 9. przedstawiono krzywe ilości wyprodukowanej energii w zależności od prędkości wiatru.

Rys. 9. Prognoza produkcji energii z turbiny wiatrowej na podstawie prędkości wiatru, rys. A. Bilski
Kolor czarny reprezentuje teoretyczną produkcję, kolor czerwony reprezentuje rzeczywistą produkcję, zaś kolor niebieski reprezentuje produkcję przewidywaną. Zarówno teoretyczne, jak i przewidywane krzywe pokrywają się z rzeczywistą krzywą produkcji energii. Ponadto z wykresu można odczytać, że produkcja energii osiąga swój pełny potencjał 3500 kW przy prędkości wiatru 13 m/s. Maksymalna prędkość wiatru wynosi 19 m/s, ale są to wartości osiągane bardzo rzadko w zbiorze danych (407 obserwacji). Średnia produkcja energii elektrycznej przy tej prędkości wiatru wynosi 3566,5 kW. Nierównomierne rozłożenie punktów powyżej i poniżej charakterystyki może być związane z nierównomiernym rozkładem prędkości wiatru wewnątrz turbiny wiatrowej.
W tabeli 5. przedstawiono wartości zastosowanych metod pomiaru błędów (R2, MAE i RMSE). Choć wszystkie kryteria oceny dokładności zastosowanych mechanizmów predykcji mieszczą się w różnych przedziałach liczbowych, możliwe jest porównanie kolejnych metod w odniesieniu do tego samego współczynnika.

Tab. 5. Wyniki zastosowanych metod oceny jakości modeli regresji
Wnioski
Na podstawie eksperymentów przeprowadzonych na zbiorze danych turbiny wiatrowej Esenköy, z wykorzystaniem różnych metod regresji, celem predykcji produkcji energii wiatrowej na podstawie prędkości wiatru można stwierdzić, że najlepszą metodą (dającą najmniejsze błędy oceny efektywności algorytmu) jest algorytm regresji bazujący na drzewie decyzyjnym. Spośród trzech zastosowanych algorytmów drzewo decyzyjne ma najmniejszą wartość MAE i RMSE (odpowiednio 144,5 i 340).
Przyszłe badania obejmą więcej czynników determinujących ilość wytwarzanej energii. Zaprezentowaną tu metodologię można również rozbudować o dodatkowe metody regresji bazujące na algorytmach sztucznej inteligencji. Ostatecznie jakość zaprezentowanych tu algorytmów regresji należy zbadać dla różnych horyzontów czasowych.
Literatura
- Yang B., Wang, J., Zhangp, X., Yu, T., Yao, W., Shu, H.: “Comprehensive Overview of Meta-Heuristic Algorithm Applications on Pv Cell Parameter Identification”, Energy Conversion and Management, vol. 208, 2020.
- Vennila C., Tits A., Sudha T.Sri, Sreenivasulu U., Pandu Ranga Reddy N., Jamal K., Lakshmaiah Dayadi, Jagadeesh P., Belay A., “Forecasting Solar Energy Production Using Machine Learning”, International Journal of Photoenergy, vol. 2022, 2022.
- de Falani, S.Y.A., Gonzalez, M.O.A., Barreto, F.M., de Toledo, J.C., Torkomain, A.L.V.: “Trends in the technological development of wind energy generation”, International Journal of Technology Management & Sustainable Development, vol. 19, no. 1, pp. 43-68(26), 2020.
- Zhou Wu, Gan Luo, Zhile Yang, Yuanjun Guo, Kang Li, Yusheng Xue: “A comprehensive review on deep learning approaches in wind forecasting applications”, CAAI Transactions on Intelligence Technology, vol 7, issue 2, pp. 129-143, 2022.
- https://wwindea.org/world-market-for-wind-power-saw-another-record-year-in-2021-973-gigawatt-of-new-capacity-added/
- Hearps P., McConnell D.: “Renewable energy technology cost review”, Melbourne Energy Institute, p.57, 2011.
- Kazi, S.: Adaptation of energy production to forecast values using external storage”, Acta Universitatis Sapientiae Electrical and Mechanical Engineering, vol. 3, pp. 51-60, 2011.
- Martinez, C., et al.: “Predicting wind turbine blade erosion using machine learning”, SMU Data Sci. Rev. 2(2), 17 (2019)
- Letcher, T.M.: “Wind energy engineering: a handbook for onshore and offshore wind turbines”, Academic Press (2017)
- Kalmikov, A.: Wind power fundamentals. In: Jain, P. (ed.) Wind Energy Engineering, pp. 17–24. Elsevier (2017)
- Soman, S.S., et al.: “A review of wind power and wind speed forecasting methods with different time horizons", In: North American Power Symposium 2010, pp. 1–8. IEEE (2010).
- Shahram Hanifi, Xiaolei Liu, Zi Lin, and Saeid Lotfian: “A critical review of wind power forecasting methods—past, present and future”, energies 13.15 (2020), p. 3764.
- Claudio Monteiro, Ricardo Bessa, V Miranda, Audun Botterud, Jianhui Wang, G Conzelmann, et al.: “Wind power forecasting: State-of-the-art 2009”, Tech. rep. Argonne National Lab.(ANL), Argonne, IL (United States), 2009.
- Nielsen T.S., Joensen A., Madsen H., Landberg L., Giebel G.: “A new reference for wind power forecasting”, Wind Energy 1 (1), pp. 29–34, 1998.
- Al-Yahyai S., Charabi Y., Gastli A.: “Review of the use of Numerical Weather Prediction (NWP) Models for wind energy assessment”, Renewable & Sustainable Energy Reviews, vol. 14, no. 9, pp. 3192- 3198, 2010.
- Shukur O.B., Lee M.H.: “Daily wind speed forecasting through hybrid kf-ann model based on arima”, Renew. Energy 76, pp. 637–647, 2015.
- Aghajani A., Kazemzadeh R., Ebrahimi A.: “A novel hybrid approach for predicting wind farm power production based on wavelet transform, hybrid neural networks and imperialist competitive algorithm”, Energy Convers. Manage. 121, pp. 232–240, 2016.
- Sun W., Wang Y.: “Short-term wind speed forecasting based on fast ensemble empirical mode decomposition, phase space reconstruction, sample entropy and improved back-propagation neural network”, Energy Convers. Manage. 157, pp. 1–12, 2018.
- Liu H., Mi X., Li Y.: “Comparison of two new intelligent wind speed forecasting approaches based on wavelet packet decomposition, complete ensemble empirical mode decomposition with adaptive noise and artificial neural networks”, Energy Convers. Manage. 155, pp. 188–200, 2018.
- Li L-L, Zhao X., Tseng M-L, Tan R.R.: “Short-term wind power forecasting based on support vector machine with improved dragonfly algorithm”, Journal of Cleaner Production, vol. 242, 2020.
- Mingshuai L., Zheming C., Jing Z., Long W., Chao H., Xiong L.: “Short-term wind speed forecasting based on the Jaya-SVM model”, International Journal of Electrical Power & Energy Systems, vol. 121, 2020.
- Wang H-K, Song K., Cheng Y.: “A hybrid forecasting model based on cnn and informer for short-term wind power”, Frontiers in Energy Research, vol. 9, 2022.
- Ne Y., Bo H., Zhang W., Zhang H.: “Research on Hybrid Wind Speed Prediction System Based on Artificial Intelligence and Double Prediction Scheme”, Complexity, vol. 2020, 2020
- Tian Z., Ren Y., Wang G.: “Short-term wind power prediction based on empirical mode decomposition and improved extreme learning machine”, J. Electr. Eng. Technol. 13 (5), pp. 1841–1851, 2018.
- Zhang C., Wei H., Zhao J., Liu T., Zhu T., Zhang K.: “Short-term wind speed forecasting using empirical mode decomposition and feature selection”, Renew. Energy 96, pp. 727–737, 2016.
- Huang N. E., Shen Z., Long S. R., Wu M. L. C., Shih H. H., Zhang Q. N., Yen N. C., Tung C. C.: “The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis”, Proceedings Mathematical Physical & Engineering Sciences, vol. 454, no. 1971, pp. 903- 995, 1998.
- Du S. C., Liu T., Huang D. L., Li G. L.: “An optimal ensemble empirical mode decomposition method for vibration signal decomposition”, Journal of Vibration & Acoustics, vol. 139, no. 3, 2017.
- Meng A., Ge J., Yin H., Chen S.: “Wind speed forecasting based on wavelet packet decomposition and artificial neural networks trained by crisscross optimization algorithm”, Energy Convers. Manage. 114, pp. 75–88, 2016.
- Tian Z., Ren Y., Wang G.: “Short-term wind speed prediction based on improved pso algorithm optimized em-elm”, Energy Sources Part A 41 (1), pp. 26–46, 2019.
- Hyndman, R.J., Koehler, A.B.: “Another look at measures of forecast accuracy”, International Journal of Forecasting, vol. 22, no. 4, pp. 679-688, 2006.