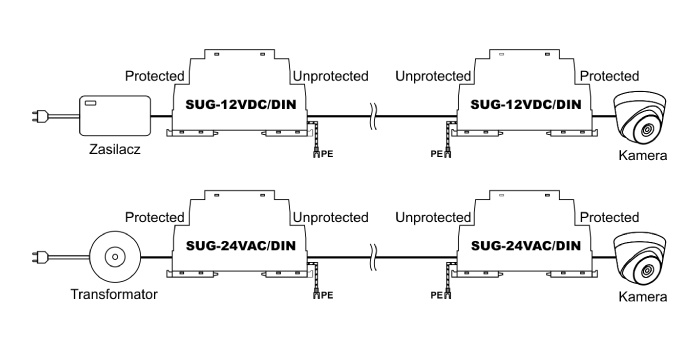
Problematyka niezawodności zasilania gwarantowanego oraz systemu informatycznego w obiektach data center (cześć 2.)
The chosen aspects of the reliability of guaranteed power supply and information system in the data centers buildings

Widok serwerowni
Fot. K. Kuczyński
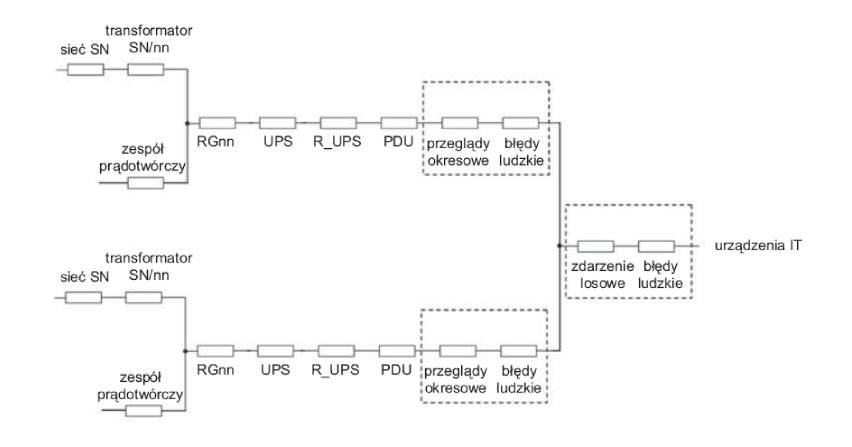
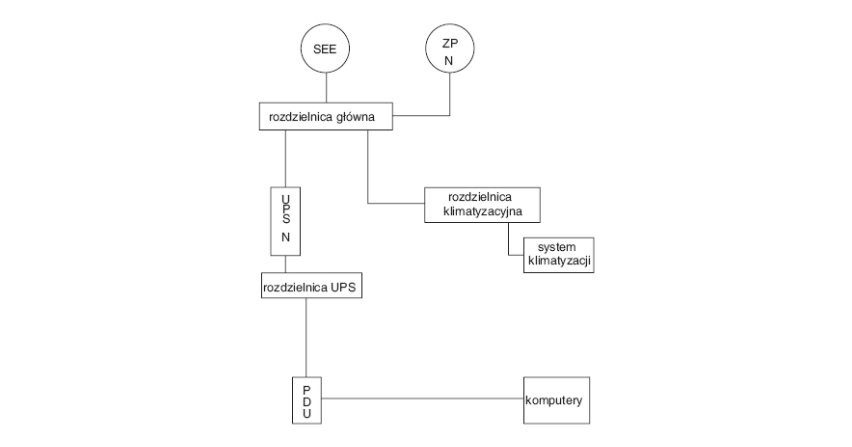
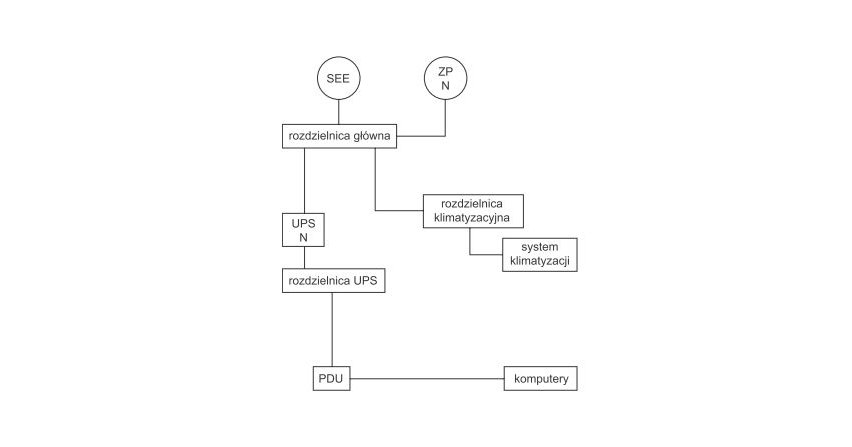
Zagadnienie niezawodności zasilania gwarantowanego w obiektach data center jest bardzo istotne na etapie zarówno budowy, jak i eksploatacji obiektu.
Zobacz także
dr inż. Karol Kuczyński Na co zwracać uwagę przy wyborze zasilacza UPS?

Występowanie stanów awaryjnych lub innych zaburzeń w systemie elektroenergetycznym, jak również oddziaływanie czynników atmosferycznych wpływa na powstawanie przerw w dostawach energii. Oddziałujące zaburzenia...
Występowanie stanów awaryjnych lub innych zaburzeń w systemie elektroenergetycznym, jak również oddziaływanie czynników atmosferycznych wpływa na powstawanie przerw w dostawach energii. Oddziałujące zaburzenia bądź przerwy w zasilaniu odbiorników mogą powodować utratę przetwarzanych danych, uszkodzenie urządzeń, przegrzewanie się systemów z uwagi na wyłączenie klimatyzacji, a w konsekwencji ich natychmiastowe zatrzymanie lub uszkodzenie. Zabezpieczeniem przed przytoczonymi konsekwencjami jest zastosowanie...
Impakt SA Nowa rodzina zasilaczy PowerWalker UPS VFI EVS 5 kVA z magazynami energii

Seria PowerWalker VFI EVS to nowa generacja zasilaczy UPS, oferująca długi czas podtrzymania dzięki zastosowaniu baterii LiFePO4 o 40% mniejszej masie i wymiarach w odniesieniu do klasycznych baterii kwasowo-ołowiowych....
Seria PowerWalker VFI EVS to nowa generacja zasilaczy UPS, oferująca długi czas podtrzymania dzięki zastosowaniu baterii LiFePO4 o 40% mniejszej masie i wymiarach w odniesieniu do klasycznych baterii kwasowo-ołowiowych. Zastosowana topologia podwójnej konwersji (VFI-SS-311) gwarantuje najwyższy poziom bezpieczeństwa, a wyspecjalizowane układy utrzymują współczynnik mocy PF na poziomie > 0.99. Oczywiście zależy on od podłączonych urządzeń odbiorczych. Wszelkie informacje o stanie UPS widoczne są na...
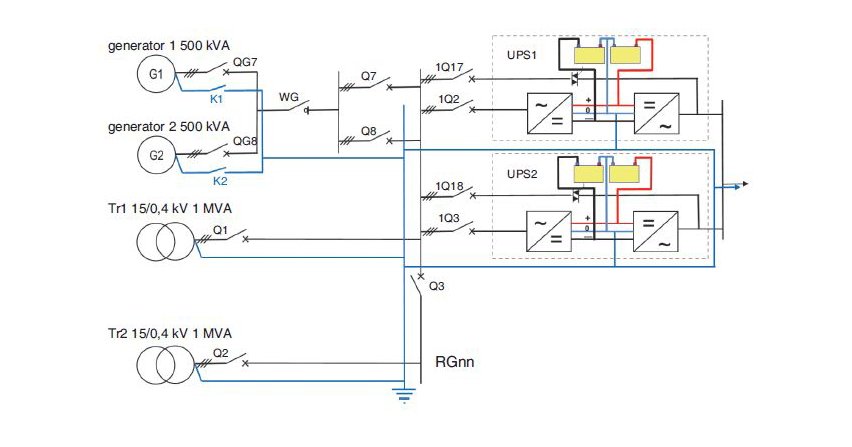
Riello Delta Power Sp. z o.o. Projekt przygotowania zespołów prądotwórczych na potrzeby funkcjonowania nowych bloków gazowo-parowych w elektrowni

Firma Riello Delta Power Sp. z o.o. na przełomie lat 2022 i 2023 zrealizowała projekt zabudowy, produkcji, dostarczenia i instalacji dwóch zespołów prądotwórczych na potrzeby funkcjonowania nowych bloków...
Firma Riello Delta Power Sp. z o.o. na przełomie lat 2022 i 2023 zrealizowała projekt zabudowy, produkcji, dostarczenia i instalacji dwóch zespołów prądotwórczych na potrzeby funkcjonowania nowych bloków gazowo-parowych w jednej z kluczowych dla polskiego systemu energetycznego elektrowni w Polsce północno-zachodniej.
Niezawodność systemu informatycznego w data center jest szerszym pojęciem związanym m.in.: z czynnikiem ludzkim, jakością sprzętu IT, jak również właściwymi parametrami środowiska serwerowni. Wysoka niezawodność nie zawsze gwarantuje wysoką dostępność systemu.
Dlaczego wysoka niezawodność jest tak istotna w obiektach typu data center?
Brak możliwości działania kluczowych aplikacji na skutek braku zasilania lub awarii infrastruktury informatycznej to w wielu obszarach biznesu bardzo wysokie nieoczekiwane koszty. Kosztowna jest również w wielu przypadkach utrata danych w wyniku awarii zasilania elektrycznego. Koszty wizerunkowe wynikające np. ze zmniejszonego zaufania klientów do firmy na skutek problemów z dostępem do systemu informatycznego również mogą być znaczące.
Według statystyk amerykańskich 91% obiektów typu data center doświadczyło nieplanowanej przerwy w działaniu w ciągu 24 miesięcy, a ponad 70% wszystkich awarii w data center jest spowodowanych przez czynnik ludzki [2, 16].
Awaria dotyczyć może, na co należy zwrócić uwagę, zarówno braku zasilania elektrycznego, jak i braku działania systemu informatycznego przy działającym zasilaniu elektrycznym.
Według badań firmy Gartner w USA, około 80% zaników w działaniu systemów niezwiązanych z brakiem zasilania elektrycznego wynikało z błędnych działań administratorów systemu oraz wykonawców systemu [3].
Nieco inne statystyki podaje Ponemon Institute [12]. Na podstawie danych z 41 obiektów data center różnej wielkości i z różnych branży ustalono, że najczęstszą przyczyną nieplanowanych przestojów systemu komputerowego były awarie zasilaczy UPS. Szczegóły przedstawiono na rysunku 1.

Rys. 1. Główne przyczyny nieplanowanych przestojów (opracowano na podstawie [12])
„USA Today” opublikowało analizę około 200 obiektów typu data center, która wykazała, że w 80% obiektów godzinny koszt przestojów przekroczył kwotę 50 000 $ [3].
W 25% przypadków godzinny koszt przestojów przekroczył olbrzymią kwotę 500 000 $.
Średni roczny czas przerwy wyniósł 14 godzin.
Koszt przestoju silnie zależy od profilu działalności.
W sektorze mediów godzinny koszt przestoju to około 90 tysięcy dolarów.
W przypadków dużych firm brokerskich koszt ten wynosić może nawet 6,5 miliona dolarów.
Średni koszt za minutę przestojów w obiektach typu data center w USA wzrósł o 41% od 5614 USD w 2010 do 7908 USD w 2013.
Natomiast w Polsce już 10 min zatrzymania data center jednej z sieci marketów kosztowało ponad 12 milionów złotych. Mówimy tu tylko o zatrzymaniu procesu logistycznego, nie mówiąc o zatrzymaniu procesów sprzedaży [4].

Tab. 1. Koszty przestojów w obiektach data center w zależności od niezawodności i dostępności systemu (opracowano na podstawie [3])
W tabeli 1. przedstawiono szacunkowe koszty przestojów w obiektach data center w zależności od dostępności i niezawodności systemu.
W obiektach o najwyższej niezawodności liczba przerw jest oczywiście najmniejsza. Najmniejszy jest również czas pojedynczej przerwy, ale również, co bardzo istotne, średni koszt pojedynczej przerwy.
W bilansie ogólnych kosztów wynikających z przerw w działaniu, obiekty data center o niskiej niezawodności i dostępności wypadają oczywiście najgorzej.
Koszty te są, na co warto zwrócić uwagę, 40-krotnie większe niż w przypadku obiektów data center o najwyższej niezawodności.
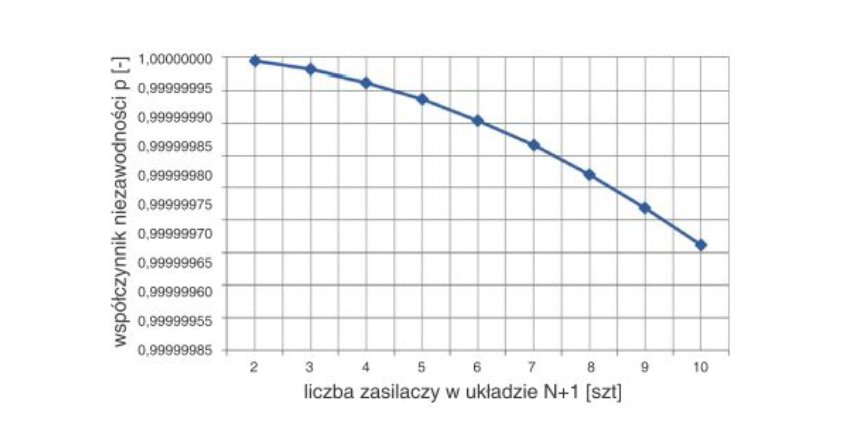
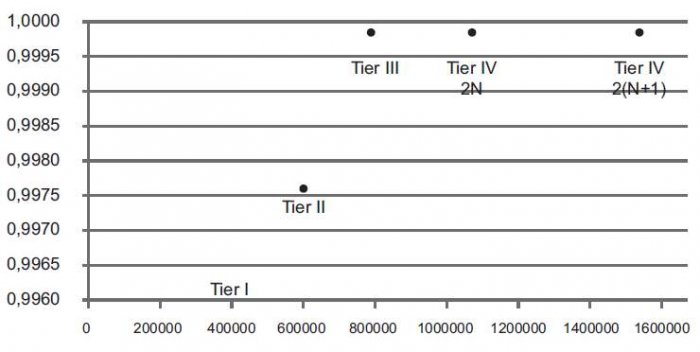
Ewidentnie wynika stąd, że warto ponieść wyższe koszty na etapie budowy data center w celu zwiększenia poziomu niezawodności. Warto jednak pamiętać, że wyjątkowo wysoka niezawodność jest znacząco droższa od wysokiej niezawodności – koszty rosną znacznie dynamiczniej niż poziom niezawodności, co ilustrują rysunek 2. i rysunek 3.

Rys. 2. Procentowy koszt budowy poszczególnych układów zasilania Tier w odniesieniu do kosztu układu zasilania w kategorii Tier I [5]

Rys. 3. Współczynnik dostępności w zależności od kosztów budowy dla poszczególnych kategorii Tier [6]
SLA (ang. Service Level Agreement) to umowa dotycząca poziomu usług, która w szczegółowy sposób określa ustalone pomiędzy stronami parametry świadczonych usług [1]. Usługi informatyczne są w pewnego rodzaju zależności drzewiastej. Na szczycie mamy usługi świadczone dla biznesu, poniżej aplikacje wspierające te usługi, jeszcze niżej – infrastrukturę i sieć. Utworzenie katalogu usług i podzielenie ich w odpowiednie zakresy jest podstawą do określenia warunków utrzymania. Dostępność to zdolność systemu informatycznego do poprawnego wypełniania powierzonego mu zadania w ciągu zdefiniowanego okresu czasu. Zazwyczaj dostępność jest określana w umowie z firmą zajmującą się utrzymaniem systemu lub infrastruktury. Gwarantowany roczny czas braku dostępu do danych (tzw. czas SLA) w krajowych obiektach data center wynosi maksymalnie do 90 minut. Dostępność systemu oznacza jego działanie jako całości. Innymi słowy, czas naprawy awarii jednego z wielu serwerów to czas niedostępności systemu – nie każda przerwa w działaniu systemu jest więc bezpośrednio związana z brakiem zasilania elektrycznego. Najbardziej zaawansowane systemy są dostępne przez 99,999% czasu – oznacza to 300 sekund (5 minut) niedostępności systemu w ciągu jednego roku (tab. 2.).
Jakiego poziomu dostępności spodziewają się firmy posiadające data center? W przeprowadzonej w USA ankiecie, 10% firm posiadających obiekt typu data center uważa, że potrzebuje poziomu dostępności powyżej 99,999%. Poziom 99,999% jest wystarczający dla 9% firm. Dla 30% firm wystarczający wydaje się poziom dostępności 99,99%, a dla 39% wystarczający jest poziom dostępności 99,9%. W przypadku jedynie 15% firm wystarczający jest dla nich poziom dostępności równy 99%. Poziom dostępności na poziomie poniżej 99% był wystarczający jedynie dla 4% firm [3]. Szczegółowo przedstawiono preferencje na rysunku 4.

Tab. 2. Procentowa dostępność systemu a czas niedostępności w ciągu 1 miesiąca oraz 1 roku (opracowano na podstawie [1])

Rys. 4. Potrzeby ankietowanych obiektów data center odnośnie wartości dostępności systemu (opracowano na podstawie [3])
Efektywne chłodzenie elementem niezawodności systemu komputerowego
Niezawodność pracy systemu to również wydajne i niezawodne chłodzenie sprzętu IT w serwerowni.
Standardowa temperatura w pomieszczeniach serwerowni powinna wynosić około 24°C przy wilgotności względnej powietrza około 50%. Szczegółowo określa te parametry standard ASHRAE TC 9.9 2011 – minimalna temperatura 18°C, maksymalna temperatura 27°C, minimalna wilgotność 35%, maksymalna wilgotność 60%.
Natomiast maksymalna zmiana temperatury nie powinna być większa niż 5°C na godzinę.
Zbyt wysoka wilgotność powietrza może być powodem kondensacji pary wodnej mogącej powodować zwarcia w układach elektronicznych sprzętu IT, a zbyt niska wilgotność powietrza to ryzyko zbyt silnych oddziaływań elektrostatycznych.
Pomiar temperatury powinien odbywać się na wysokości 1,5 m od poziomu podłogi wzdłuż linii środkowej zimnego korytarza oraz w istotnych miejscach dla sprzętu IT.
Brak chłodzenia sprzętu komputerowego (serwery, aktywny sprzęt sieciowy) groziłby wzrostem temperatury do wartości, które działają destrukcyjnie na sprzęt, a w konsekwencji mogą powodować nieplanowane przerwy w działaniu systemu.
Przykładowo, temperatura wewnątrz obudowy komputera/serwera powinna być utrzymana na poziomie 30–40°C i absolutnie nie może przekraczać 55°C (temperatura uśredniona) [7].
Oczywiście część podzespołów, takich jak procesory i karty graficzne, pracuje przy znacznie wyższych wartościach wydzielanego ciepła (radzą sobie nawet z temperaturą 80–90°C), ale tak wysoka temperatura występuje tylko lokalnie. W temperaturze 150°C krzem zaczyna przewodzić prąd w podobny sposób jak metal – w układzie nagrzanym do temperatury krytycznej wszystkie tranzystory zostają w nim zwarte i znikają zaprojektowane struktury logiczne – uszkodzenia są nieodwracalne. W przypadku procesorów firmy Intel natychmiastowe, nieodwracalne zniszczenie układu następuje w temperaturze około 135°C, a w przypadku procesorów firmy AMD w temperaturze około 125°C.
Układy scalone (dobrych producentów) są tak projektowane aby w zakresie temperatur 25–65°C były w stanie pracować w sposób ciągły przez minimum 10 lat.
Przykładowe maksymalne temperatury pracy to:
- 95°C dla procesora (przekroczenie tej temperatury skraca „życie” procesora do około 1,5 roku),
- 80°C dla karty graficznej,
- 60°C dla dysku twardego,
- 45°C dla płyty głównej (kondensatory, rezystory)
- oraz 45°C dla nagrywarki DVD (po przekroczeniu 60°C plastikowe mocowania soczewek oraz optyka z plastiku zaczyna się deformować i prawidłowe zogniskowanie wiązki laserowej nie jest możliwe).
W przypadku przegrzania serwera można oczekiwać restartów systemu lub zawieszenia się systemu komputerowego, a w najlepszym przypadku spowolnienia pracy wynikające z zadziałania mechanizmów zabezpieczających układy przed przegrzaniem (np. zmniejszenie częstotliwości taktowania procesorów).
W kontekście monitoringu parametrów serwerowni warto wspomnieć o zaawansowanych urządzeniach PDU (ang. Power Distribution Unit), czyli listwach dystrybucji zasilania stosowanych w szafach serwerowych.
W serwerowniach stosuje się głównie listwy pionowe montowane z tyłu szafy rackowej – po dwie na szafę, każda na osobną linię zasilania.
Listwy mogą mieć różne parametry użytkowe oraz funkcje.
Przykładem jednych z bardziej rozbudowanych urządzeń PDU są zarządzalne listwy dystrybucji zasilania – Network Power Manager V (NPM V) (fot. 1.).

Fot. 1. Pozioma zarządzalna 19” listwa dystrybucji zasilania BKT NPM V – widok z przodu oraz z tyłu [11]
Urządzenia mające wersję jednofazową oraz trójfazową (prąd do 32 A) łączą w sobie funkcje dystrybucji energii oraz mają dodatkowe funkcje [10]:
- alarmu,
- monitoringu,
- zarządzania
- oraz konfiguracji.
Zarządzalne PDU ma interfejsy Ethernet, SNMP (V1, V2c, V3), HTTP, SSH, Telnet, SMTP oraz złącze USB do komunikacji bezprzewodowej.
Alarmy oprócz ich wizualizacji na panelu kontrolnym oraz generacji dźwięku (wewnętrzny wbudowany alarm) wysyłane są także na wskazane adresy e-mail.
Ponadto alarmy widoczne są z poziomu interfejsu www.
Urządzenie może współpracować z podpiętymi do urządzenia:
- czujnikami temperatury i wilgotności (oprócz bieżących wartości odnotowuje wartości minimalne oraz maksymalne),
- czujnikiem zalania,
- czujnikiem dymu
- oraz czujnikami otwarcia drzwi (również osłon bocznych szafy).
Listwa monitoruje ponadto zużycie energii z całej listwy oraz z każdego gniazdka, pokazuje bieżącą wartość współczynnika mocy, napięcie zasilania oraz natężenie prądu dla każdego gniazda, oraz całej listwy, pobór mocy z całej listy oraz z każdego gniazda.
Urządzenie odnotowuje ponadto minimalne oraz maksymalne wartości napięcia, oraz prądu.
Urządzenia NPM V zawierają ponadto porty RJ45 do kaskadowego łączenia kilku urządzeń w łańcuch wielu urządzeń PDU korzystających z jednego adresu IP.
Konfiguracji podlega np. obciążenie prądowe każdego gniazda oraz każdej fazy z ustalonymi wartościami maksymalnymi oraz czasem opóźnienia przy sekwencyjnym wyłączaniu.
Konfigurowane są również wszystkie te wartości, które uruchamiają alarm po przekroczeniu zdefiniowanych w konfiguracji wartości.
Do wyposażenia dodatkowego PDU zaliczyć można:
- wyłącznik nadmiarowoprądowy,
- wyłącznik różnicowoprądowy zintegrowany z wyłącznikiem nadmiarowoprądowym
- oraz wymienny moduł przeciwprzepięciowy z filtrem.
Warto dodać, że w przypadku zasilania wielu szaf teleinformatycznych do monitorowania zastosować można np. system EMS (System Monitorowania Środowiska), za pomocą którego można nadzorować środowisko i zasilanie w jednej lub kilku szafach (maksymalnie 11 jednostek typu slave) (fot. 2.).
Na całość systemu składają się: jednostka centralna (master), jednostki wykonawcze (slave), koncentrator oraz listwy zasilające PDU z modułami MPD [10]. Do systemu EMS nie podpina się listew zarządzanych, takich jak NPM, ale listwy PDU z modułami pomiarowymi, które tylko monitorują parametry elektryczne i środowiskowe z całej listwy. Szczegóły połączeń w systemie przedstawiono na rysunku 5.
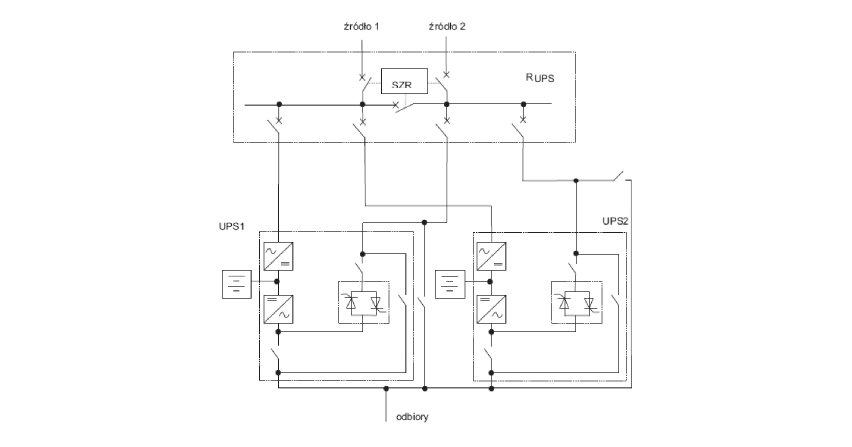
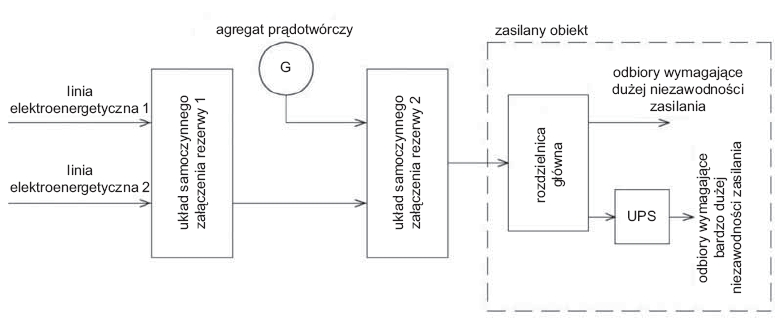
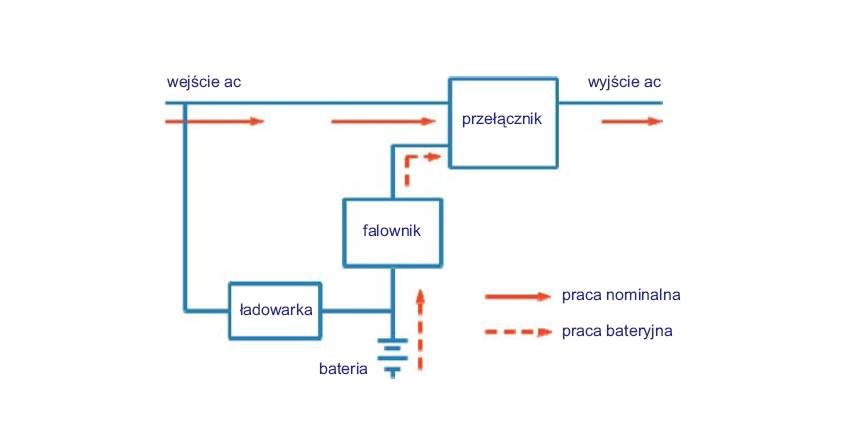
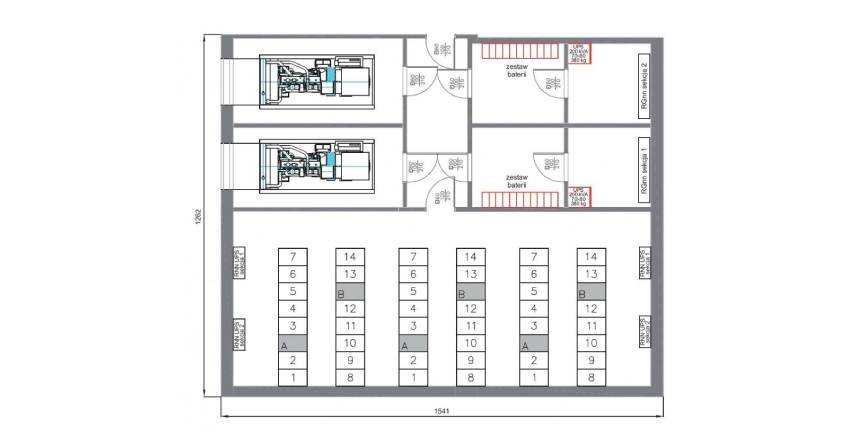
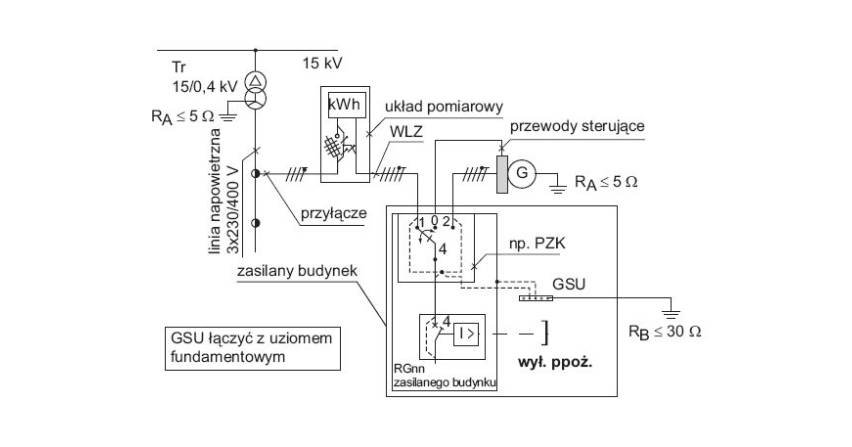
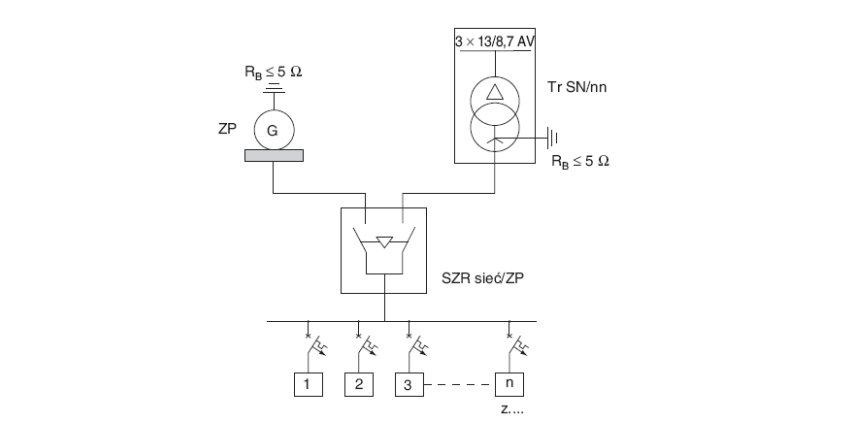
Problem właściwej temperatury dotyczy oczywiście również elementów zasilania gwarantowanego. Przykładowo UPS musi być zaprojektowany zgodnie z normą IEC62040 do maksymalnej temperatury pracy nie większej niż 40°C. Według normy EN 50600-2-3:2014 pomieszczenia, w których znajdują się zespoły prądotwórcze, oraz pomieszczenia, w których znajdują się transformatory, powinny mieć temperaturę od 10°C do 35°C, jeśli nie ma dokładnych wytycznych. Pomieszczenie, w którym znajdują się baterie akumulatorów, powinno mieć natomiast temperaturę od 19°C do 22°C, o ile producent nie podaje inaczej.
Proces doboru klimatyzacji precyzyjnej dla obiektu data center jest obecnie procesem oceny tzw. TCO (ang. Total Cost of Ownership), czyli całkowitego kosztu posiadania. TCO to suma wszystkich kosztów danego rozwiązania począwszy od jego zakupu, poprzez użytkowanie, aż do likwidacji. Na TCO składają się w tym przypadku m.in. [4]:
- koszt zakupu urządzeń i instalacji (systemu),
- prognozowane koszty eksploatacji – energii elektrycznej i serwisu z materiałami eksploatacyjnymi
- tzw. czas SLA (związany z kosztami), na który składają się:
- czas reakcji serwisu (czas, w którym dostawca usługi serwisowej reaguje na zgłoszenie klienta w formie albo potwierdzenia przyjęcia zgłoszenia, albo telefonu zwrotnego do użytkownika systemu lub przyjazdu na obiekt w celu oceny problemu/usterki)
- i czas doprowadzenia systemu do 100% sprawności (czas, w którym serwis naprawi i uruchomi system klimatyzacji). Oczywiście im krótszy czas SLA jest gwarantowany, tym koszty dla firmy są wyższe.

Fot. 2. System EMS – jednostka centralna [11]

Rys. 5. System EMS – przykładowa konfiguracja systemu [11]
Inny istotny element związany z utrzymaniem m.in. właściwej temperatury w serwerowni i mający wpływ na koszt pracy systemu to efektywność wg PUE (ang. Power Usage Effectiveness). Efektywność zużycia energii (PUE) to jeden z najważniejszych wskaźników określających parametry data center. PUE obliczamy według wzoru (1):

Wzór 1
Im mniejsza wartość PUE (bliższa liczbie 1), tym niższe koszty związane z opłatami za energię elektryczną.
W nowoczesnych data center wartość PUE może wynosić około 1,3 i mniej. W skrajnie niekorzystnym przypadku, np. PUE = 3, gdy do działania sprzętu IT potrzeba np. 10 kW mocy to całkowite zapotrzebowanie na moc wynosi aż 30 kW.
Warto dodać, że według analiz Uptime Institute średnia wartość PUE w roku 2011 wynosiła 1,89, a w roku 2014 zmalała do wartości 1,7 [2]. Pobór mocy przez systemy chłodnicze stanowi dużą część całkowitego zapotrzebowania na moc w obiekcie data center. Ilustruje to rysunek 6. W tym przykładowym przypadku wskaźnik PUE wynosi aż 2,7.
Oczywiście im bardziej wyrafinowany system chłodzenia, tym wartość wskaźnika PUE jest mniejsza, maleją koszty opłat za energię elektryczną – ilustruje to rysunek 7., dla którego wartość wskaźnika PUE wynosi tylko 1,7. Zmiana nastąpiła w wyniku zastosowania energooszczędnych rozwiązań w systemie klimatyzacji przykładowego data center przedstawionego na rysunku 6.
Według statystyk amerykańskich [2] 12% ankietowanych obiektów typu data center pożąda PUE o wartościach ekstremalnie niskich czyli 1,0–1,2, 47% data center chciałoby wartości PUE 1,2–1,5, natomiast 37% data center byłoby zadowolonych z wartości PUE 1,5–2,0.

Rys. 6. Przykładowy rozkład energii w data center (opracowano na podstawie [8])

Rys. 7. Przykładowy rozkład energii w data center po zastosowaniu energooszczędnych technologii w zakresie klimatyzacji (opracowano na podstawie [8])
Istnieje wiele rozwiązań energooszczędnych, które pozwalają znacząco obniżyć wartość wskaźnika PUE oraz całkowite zapotrzebowanie na energię.
Jednym z najlepszych sposobów na poprawienie efektu chłodzenia w serwerowniach są tzw. zamknięcia stref gorących lub zimnych. Zastosować można np. szafy chłodnicze (nadmuch pod podłogą techniczną) z użyciem zabudowy, np. typu „NAUTILUS” [8].
Interesującym, ale dość drogim rozwiązaniem (nie do każdej strefy klimatycznej), jest wykorzystanie w klimatyzacji systemu Free Cooling (darmowy chłód) – jest to system pozwalający na wytwarzanie schłodzonej wody bez angażowania sprężarek chłodniczych, a wykorzystującym tylko niską temperaturę powietrza zewnętrznego w chłodnych porach roku [8].
Samodzielne naturalne chłodzenie w warunkach krajowych jest możliwe do 20% czasu eksploatacji, natomiast przez około 18% czasu eksploatacji jako chłodzenie wspomagające w systemie klimatyzacji wykorzystującym energię elektryczną. Oprócz oszczędności w zużyciu energii, przedłuża się również żywotność sprężarek.
W przypadku wyrafinowanych rozwiązań w zakresie systemów klimatyzacji koszty na etapie budowy/modernizacji data center są oczywiście wyższe – należy więc i ten aspekt kosztów brać pod uwagę.
Najrozsądniejszym rozwiązaniem wydaje się symulacja kosztów całkowitych (nakłady początkowe na budowę (wielowariantowe w zależności od zastosowanych technologii) oraz koszty roczne związane z działaniem data center) dla pewnego okresu czasu, np. 10 lat, i wybór takich rozwiązań, które przy zachowaniu wymaganej niezawodności oraz wymaganych standardów będą najkorzystniejsze ekonomicznie.
Warto wiedzieć, że globalne zużycie energii przez obiekty data center na świecie wynoszące 322 TWh w 2012 roku stanowiło około 1,8% całkowitego zużycia energii elektrycznej [9].
Podsumowanie
Poziom Tier IV daje najwyższą dostępność zasilania dla odbiorów końcowych, ale jest jednocześnie najdroższy, ponieważ wymaga zastosowania wielu, często drogich elementów nadmiarowych. Ponadto, pomimo większych kosztów projektu, budowy oraz utrzymania obiektu, otrzymuje się współczynnik dostępności na poziomie niewiele większym niż w obiekcie z poziomem Tier III.
Kompromisowym rozwiązaniem wydaje się wybór poziomu Tier III, który w przybliżeniu może kosztować 50% więcej od wyboru poziomu I lub II, ale jego dostępność będzie kilkukrotnie wyższa [13, 14, 15].
Właściwy, efektywny system klimatyzacji z redundancją jest również istotnym elementem wpływającym na dostępność systemu komputerowego. Przyczyną awarii może być usterka, np. serwera, wynikająca z przegrzania jego elementów. Inwestycje w wysokiej jakości systemy klimatyzacji są więc istotne.
Według statystyk [2, 16] błędy ludzkie są odpowiedzialne za 70% zaników działania obiektów typu data center.
Właściwe przeszkolenie personelu, odpowiednie przepisy dotyczące pracy i kontrola ich przestrzegania, właściwe procedury obsługi i konserwacji elementów systemu są również bardzo istotnym elementem wpływającym na jego niezawodność.
Eliminując chociaż część błędów wynikających z działań człowieka, niezawodność systemu mogłaby znacząco wzrosnąć. Inwestycje w jakość pracy personelu w celu minimalizacji błędów wynikających z ich działań są na pewno warte poniesienia i raczej niezbyt wysokie w porównaniu z dalszą rozbudową redundancji systemów.
Bardzo istotnym elementem związanym z zapewnieniem wysokiej niezawodności systemu jest również monitoring środowiskowy pozwalający odpowiednio szybko reagować na potencjalne zagrożenia (np. uszkodzenia baterii w systemach UPS, zbyt wysoka temperatura w pomieszczeniu, zakłócenia w sieci zasilającej, przekroczenie dopuszczalnej wartości prądu w obwodzie itd.) i zapobiegać powstaniu awarii, czyli działania sprzyjające zachowaniu jak najwyższej wartości czasu MTBF dla systemu.
Gwarancja szybkiego dojazdu serwisu w przypadku awarii, posiadanie fachowego personelu serwisowego w data center zapewniającego maksymalnie krótki czas naprawy usterki, to także ważne elementy wpływające na zmniejszenie z kolei wartości czasu MTTR dla systemu (większa dostępność systemu).
Bardzo ważna jest ponadto automatyzacja reakcji na określone zagrożenia. Dbałość o przestrzeganie wymaganych zakresów przeglądów okresowych i ich terminów to również element prewencyjny minimalizujący prawdopodobieństwo awarii.
Literatura
- Karwatka P: Co to jest SLA i jakie powinna mieć parametry?, 6.11.2012, http://ideas2action.pl/
- Severina L.: Data Centre Trends – Now and in the Future, Symposium Uptime Institute, Santa Clara, 20-22 may 2014.
- Perlin M.: Downtime, outages and failures – understanding their true costs, http://www.evolven.com/blog/downtime-outages-and-failures-understanding-their-true-costs.html
- Biernacki B.: Aspekty biznesowe serwisu klimatyzacji w data center, 24.03.2012, http://www.chlodnictwoiklimatyzacja.pl/
- Piotrowski P., Pająk R.: Analiza układów zasilania dla obiektu typu data center w zależności od wymaganego poziomu niezawodności, część 1 – porównanie kosztów budowy poszczególnych układów zasilania, Elektro.info nr. 12/2012
- Piotrowski P., Pająk R.: Analiza układów zasilania dla obiektu typu data center w zależności od wymaganego poziomu niezawodności, część 2 – porównanie niezawodności układów zasilania w standardach Tier, Elektro.info nr. 1/2/2013
- Bieńkowski M.: Pecetowe upały, CHIP, luty 2006,
- Piechulek M.: Serwerownie, data center, Centra przetwarzania danych, prezentacja firmy BKT Elektronik 3.07.2013,
- http://www.datacenterdynamics.com/
- Łapiński M: Systemy dystrybucji energii, prezentacja firmy BKT Elektronik, 20.10.2014,
- www.bkte.pl
- Calculating the Cost of Data Center Outages, Ponemon Institute Research Report, 2011
- Piotrowski P.: Aspekty elektryczne sieci komputerowych, wydanie II rozszerzone, Oficyna Wydawnicza Politechniki Warszawskiej, Warszawa 2011
- Piotrowski P., Derlacki M.: Klasyfikacja niezawodności dla obiektów typu data center, Elektro.info nr 6/2014,
- Piotrowski P.: Niezawodność zasilania gwarantowanego dla obiektów typu data center, Elektro.info nr 10/2014.
- Uptime Institute – AIRs Abnormal Incident Reports database, 2012
![Fot. 1. Pozioma zarządzalna 19” listwa dystrybucji zasilania BKT NPM V – widok z przodu oraz z tyłu [11]](https://www.elektro.info.pl/media/cache/typical_view/data/201905/problematyka-niezawodnosci-zasilania-fot01.jpg)
![Fot. 2. System EMS – jednostka centralna [11]](https://www.elektro.info.pl/media/cache/typical_view/data/201905/problematyka-niezawodnosci-zasilania-fot02.jpg)
![Rys. 1. Główne przyczyny nieplanowanych przestojów (opracowano na podstawie [12])](https://www.elektro.info.pl/media/cache/typical_view/data/201905/problematyka-niezawodnosci-zasilania-rys01.jpg)
![Rys. 2. Procentowy koszt budowy poszczególnych układów zasilania Tier w odniesieniu do kosztu układu zasilania w kategorii Tier I [5]](https://www.elektro.info.pl/media/cache/typical_view/data/201905/problematyka-niezawodnosci-zasilania-rys02.jpg)
![Rys. 4. Potrzeby ankietowanych obiektów data center odnośnie wartości dostępności systemu (opracowano na podstawie [3])](https://www.elektro.info.pl/media/cache/typical_view/data/201905/problematyka-niezawodnosci-zasilania-rys04.jpg)
![Rys. 5. System EMS – przykładowa konfiguracja systemu [11]](https://www.elektro.info.pl/media/cache/typical_view/data/201905/problematyka-niezawodnosci-zasilania-rys05.jpg)
![Rys. 6. Przykładowy rozkład energii w data center (opracowano na podstawie [8])](https://www.elektro.info.pl/media/cache/typical_view/data/201905/problematyka-niezawodnosci-zasilania-rys06.jpg)
![Rys. 7. Przykładowy rozkład energii w data center po zastosowaniu energooszczędnych technologii w zakresie klimatyzacji (opracowano na podstawie [8])](https://www.elektro.info.pl/media/cache/typical_view/data/201905/problematyka-niezawodnosci-zasilania-rys07.jpg)
![Tab. 1. Koszty przestojów w obiektach data center w zależności od niezawodności i dostępności systemu (opracowano na podstawie [3])](https://www.elektro.info.pl/media/cache/typical_view/data/201905/problematyka-niezawodnosci-zasilania-tab01.jpg)
![Tab. 2. Procentowa dostępność systemu a czas niedostępności w ciągu 1 miesiąca oraz 1 roku (opracowano na podstawie [1])](https://www.elektro.info.pl/media/cache/typical_view/data/201905/problematyka-niezawodnosci-zasilania-tab02.jpg)